リコー 日英中3言語に対応の700億パラメータ大規模言語モデルを開発 今秋提供開始
リコー 2024年8月21日発表
リコーは、顧客の業務効率化や課題解決での活用を目的に、企業ごとのカスタマイズを容易に行える700億パラメータの大規模言語モデル(LLM)を開発したと、8月21日に発表した。
製造業で特に重視される日本語・英語・中国語に対応したほか、顧客のニーズに合わせてオンプレミス・クラウドのどちらの環境でも導入可能である。入力された文章を単語などの細かい単位に分割するトークナイザーの独自改良により、高速処理と省コストを実現し、環境負荷低減にも貢献する。ベンチマークツールを用いた検証の結果、優れた性能を確認した。2024年秋から、まずは日本国内の顧客から提供を開始し、今後海外の顧客への提供も目指す。
同社は、プライベートLLMとしてのユースケース例に、機密情報を取り扱う業務である、金融業の融資審査業務等、自治体の行政サービス等、流通・小売業の顧客情報分析やマーケティング等、教員や医師の文章作成など周辺業務等を挙げているほか、日本語・英語・中国語で日々更新される社内文書のデータを利活用する業務である、製造業のRAGを活用した社内情報の検索や要約等を挙げている。
■リコーが開発した700億パラメータLLMの特徴
(1)高い日本語性能を持ち、英語・中国語にも対応可能
(2)トークナイザーの独自改良により、日本語の処理効率が同ベースモデルと比較して43%向上
(3)セキュリティを確保したオンプレミス環境で、学習~推論まで提供可能
(4)従来手法の開発と比較し、およそ50%のコスト低減および最大25%の電力消費量の削減を実現
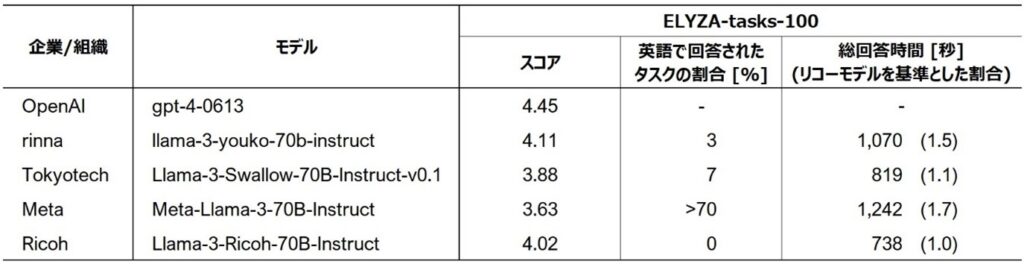
■評価結果(ELYZA-tasks-100)
複雑な指示・タスクを含む代表的な日本語のベンチマーク「ELYZA-tasks-100」において、リコーのLLMは平均で4を超える高いスコアを示した。また、比較した他のLLMはタスクによって英語で回答するケースが見られたが、リコーのLLMは全てのタスクに対して日本語で回答して高い安定性を示した。さらに、回答速度の面でも他のLLMを大きく上回り、トークナイザーの改良の効果を確認した。
製造業や金融業などセキュリティ要件の高い業界では、オンプレサーバーに導入可能な省リソースでありながら、700億パラメータの規模で、対応言語は日英中を選択可能なプライベートLLMに対する強い要望があった。こうした要望を踏まえ、リコーは、同社が開発した高性能なLLMに企業独自の情報や知識を取り入れることで、顧客ごとの業種・業務に合わせた高精度なAIモデル(プライベートLLM)を、低コスト・短期間で容易に構築することが可能であるとしている。

